

很多时候在使用Word填写文件时会遇到一些特殊字符,比如带方框的✓(2611)、方框(2610)、带方框的✗(2612)等。此时你可能会在word中的插入字符里寻找,你能找到吗?是的,有经验的话你可以找到,但是没经验的话根本找不到,这里我们将会讲一下Unicode与特殊字符之间的关系。
我们先讲一下如何使用鼠标点选操作来选择特殊字符
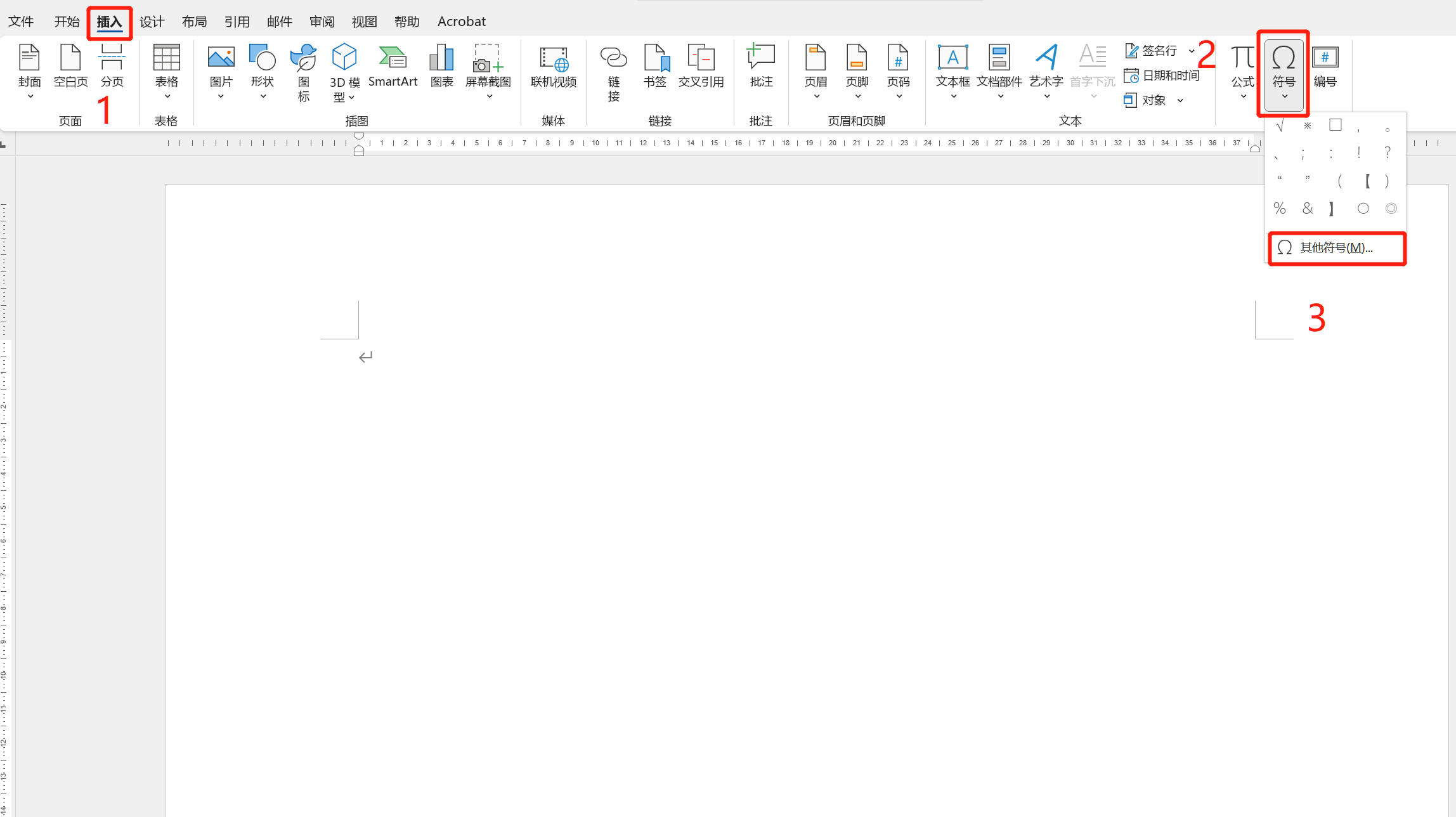
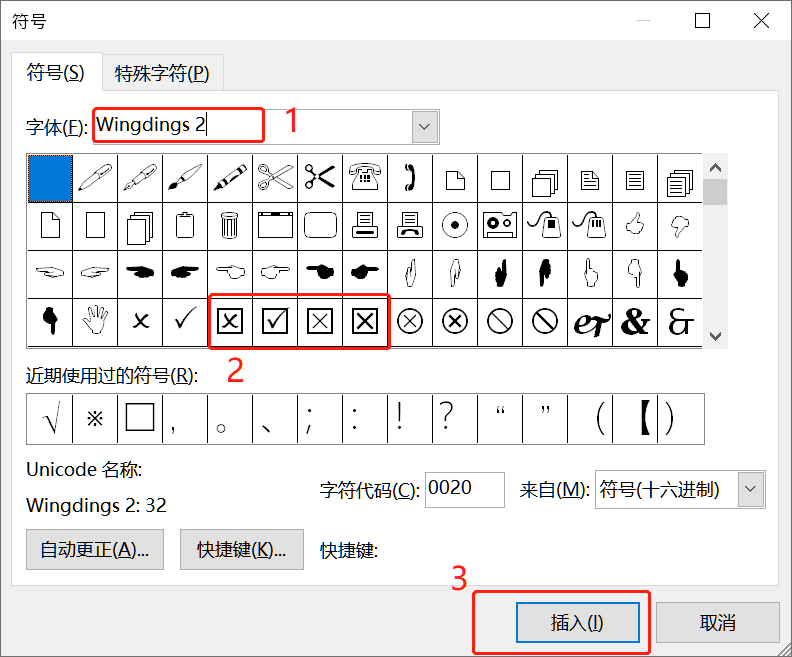
Unicode标准
Unicode,全称为Unicode标准(The Unicode Standard),其官方机构Unicode联盟所用的中文名称为统一码[1],又译作万国码、统一字符码、统一字符编码[2],是信息技术领域的业界标准,其整理、编码了世界上大部分的文字系统,使得电脑能以通用划一的字符集来处理和显示文字,不但减轻在不同编码系统间切换和转换的困扰,更提供了一种跨平台的乱码问题解决方案。Unicode由非营利机构Unicode联盟(Unicode Consortium)负责维护,该机构致力让Unicode标准取代编码空间有限、不适用于多语言环境的既有字符编码方案。
在文字处理方面,统一码为每一个字符而非字形定义唯一的代码(即一个整数)。换句话说,统一码以一种抽象的方式(即数字)来处理字符,并将视觉上的演绎工作(例如字体大小、外观形状、字体形态、文体等)留给其他软件来处理,例如网页浏览器或是文字处理器。
总结:网络中出现的所有字符都经过Unicode标准进行编码,所有的字符都涵盖在字符表中,包括英文字符、希腊字母和中文、汉语、日语等各种语言中出现的字符,也包括小黄脸表情包等可输出字符。但是根据输入法以及字体的不同,同样的Unicode编码在经过不同规范进行渲染时也会出现不同,比如苹果手机可以打出苹果公司的标志,发送至安卓手机时就会出现无法渲染的情况,我们将在后面谈到。
UTF-8编码下不同字符的字节占用
| 字符类型 | Unicode 代码点范围 | 占用字节数 | 示例 |
|---|---|---|---|
| 英文字符 (基础 $\text{ASCII}$) | $\text{U}+0000$ 到 $\text{U}+007F$ | 1 字节 | 字母 $\text{A}$ ($\text{U}+0041$)、数字 $1$、空格、标点符号。 |
| 中文字符 (常用汉字) | $\text{U}+0800$ 到 $\text{U}+\text{FFFF}$ (主要 $\text{CJK}$ 区域) | 3 字节 | 汉字 中 ($\text{U}+4E2D$)、汉字 文。 |
| 欧洲特殊字符 (带变音符号) | $\text{U}+0080$ 到 $\text{U}+07FF$ | 2 字节 | 字母 $\text{é}$ ($\text{U}+00E9$)、$\text{ü}$、欧元符号 $\text{€}$ ($\text{U}+20AC$ - 3 字节) |
| 特殊/生僻字符 ($\text{Emoji}$、生僻汉字) | $\text{U}+10000$ 及以上 ($\text{Supplementary Planes}$) | 4 字节 | —哭泣的表情 $\text{😂}$ ($\text{U}+1F602$)、甲骨文等罕见字符。 |
我们可以这样计算:打出一个英文单词可能需要1-10多个不同的拉丁字母,也就是1-10多个字节大小。打出一个中文字符则需要占用3字节大小。由此便可以计算你文档的大小。同样的一句话,可能中文占用的字节多也可能英文表述占用的字节多,这都是有可能的,具体根据字母和词语出现的次数来计算。
部分特殊字符的Unicode-16代码点表示方法
Unicode代码点代表该字符在字符表中所对应的唯一位置,在word中输入该符号对应的4位代码点后将光标移至该4位代码后使用快捷键 ALT + X 即可渲染出该代码表示的符号。
| 序号 | **字符 ** | **名称 ** | **Unicode 代码点 ** | Word 输入 (代码 + Alt+X) | Unicode 区块 |
|---|---|---|---|---|---|
| 1 | $\text{□}$ | 空白复选框 | $\text{2610}$ | $\mathbf{2610} + \text{Alt}+\text{X}$ | 杂项符号 |
| 2 | $\text{☑}$ | 带勾复选框 | $\text{2611}$ | $\mathbf{2611} + \text{Alt}+\text{X}$ | 杂项符号 |
| 3 | $\text{☒}$ | 带 $\text{X}$ 复选框 | $\text{2612}$ | $\mathbf{2612} + \text{Alt}+\text{X}$ | 杂项符号 |
| 4 | $\sqrt{}$ | 根号 | $\text{221A}$ | $\mathbf{221A} + \text{Alt}+\text{X}$ | 数学运算符 |
| 5 | $\sum$ | 求和符号 | $\text{2211}$ | $\mathbf{2211} + \text{Alt}+\text{X}$ | 数学运算符 |
| 6 | $\pi$ | 小写希腊 $\text{Pi}$ (圆周率) | $\text{03C0}$ | $\mathbf{03C0} + \text{Alt}+\text{X}$ | 希腊语和科普特语 |
| 7 | $\in$ | 属于 | $\text{2208}$ | $\mathbf{2208} + \text{Alt}+\text{X}$ | 数学运算符 |
| 8 | $\forall$ | 对于所有 | $\text{2200}$ | $\mathbf{2200} + \text{Alt}+\text{X}$ | 数学运算符 |
| 9 | $\subset$ | 是…的子集 | $\text{2282}$ | $\mathbf{2282} + \text{Alt}+\text{X}$ | 数学运算符 |
| 10 | $\text{™}$ | 商标 | $\text{2122}$ | $\mathbf{2122} + \text{Alt}+\text{X}$ | 字母类似符号 |
| 11 | $\text{©}$ | 版权 | $\text{00A9}$ | $\mathbf{00A9} + \text{Alt}+\text{X}$ | 拉丁语补充-1 |
| 12 | $\text{€}$ | 欧元符号 | $\text{20AC}$ | $\mathbf{20AC} + \text{Alt}+\text{X}$ | 货币符号 |
| 13 | $\text{→}$ | 右箭头 | $\text{2192}$ | $\mathbf{2192} + \text{Alt}+\text{X}$ | 箭头 |
| 14 | $\text{★}$ | 黑色五角星 | $\text{2605}$ | $\mathbf{2605} + \text{Alt}+\text{X}$ | 杂项符号 |
| 15 | $\text{§}$ | 节号 | $\text{00A7}$ | $\mathbf{00A7} + \text{Alt}+\text{X}$ | 拉丁语补充-1 |
| 16 | $\text{℃}$ | 摄氏度符号 | $\text{2103}$ | $\mathbf{2103} + \text{Alt}+\text{X}$ | 字母类似符号 |
系统中不仅仅有公共的字符表,还有私有字符表。私有字符表由字体提供方维护,比如之前提到的iPhone可以打出自家的苹果图标,发送至Android手机后便无法正常渲染,这就是私有字符的渲染标准不同导致的显示问题。Android设备也可以通过安装苹方以及相关字体来获得对iPhone特殊字符的支持。
ASCII
在计算机中,所有的数据在存储和运算时都要使用二进制数表示。例如,像a、b、c、d这样的52个字母(包括大写)以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,这就是编码。如果不同的计算机要想互相通信而不造成混乱,那么每台计算机就必须使用相同的编码规则,于是美国有关的标准化组织就推出了ASCII编码。
ASCII是由美国国家标准学会(American National Standard Institute,ANSI)制定的,使用标准的单字节字符编码方案,用于基于文本的数据。方案起始于50年代后期,在1967年定案。它最初是美国的标准,供不同计算机在相互通信时需共同遵守的西文字符编码标准。现已被国际标准化组织(International Organization for Standardization,ISO)定为国际标准(ISO/IEC 646),适用于所有拉丁字母。
ASCII控制字符(共33个)
| 二进制 | 十进制 | 十六进制 | 缩写 | Unicode 表示法 | 脱出字符 表示法 | 名称/意义 |
|---|---|---|---|---|---|---|
| 0000 0000 | 0 | 00 | NUL | ␀ | ^@ | 空字符(Null) |
| 0000 0001 | 1 | 01 | SOH | ␁ | ^A | 标题开始 |
| 0000 0010 | 2 | 02 | STX | ␂ | ^B | 本文开始 |
| 0000 0011 | 3 | 03 | ETX | ␃ | ^C | 本文结束 |
| 0000 0100 | 4 | 04 | EOT | ␄ | ^D | 传输结束 |
| 0000 0101 | 5 | 05 | ENQ | ␅ | ^E | 请求 |
| 0000 0110 | 6 | 06 | ACK | ␆ | ^F | 确认回应 |
| 0000 0111 | 7 | 07 | BEL | ␇ | ^G | 响铃 |
| 0000 1000 | 8 | 08 | BS | ␈ | ^H | 退格 |
| 0000 1001 | 9 | 09 | HT | ␉ | ^I | 水平定位符号 |
| 0000 1010 | 10 | 0A | LF | ␊ | ^J | 换行键 |
| 0000 1011 | 11 | 0B | VT | ␋ | ^K | 垂直定位符号 |
| 0000 1100 | 12 | 0C | FF | ␌ | ^L | 换页键 |
| 0000 1101 | 13 | 0D | CR | ␍ | ^M | CR (字符) |
| 0000 1110 | 14 | 0E | SO | ␎ | ^N | 取消变换(Shift out) |
| 0000 1111 | 15 | 0F | SI | ␏ | ^O | 激活变换(Shift in) |
| 0001 0000 | 16 | 10 | DLE | ␐ | ^P | 跳出数据通讯 |
| 0001 0001 | 17 | 11 | DC1 | ␑ | ^Q | 设备控制一(XON 激活软件速度控制) |
| 0001 0010 | 18 | 12 | DC2 | ␒ | ^R | 设备控制二 |
| 0001 0011 | 19 | 13 | DC3 | ␓ | ^S | 设备控制三(XOFF 停用软件速度控制) |
| 0001 0100 | 20 | 14 | DC4 | ␔ | ^T | 设备控制四 |
| 0001 0101 | 21 | 15 | NAK | ␕ | ^U | 确认失败回应 |
| 0001 0110 | 22 | 16 | SYN | ␖ | ^V | 同步用暂停 |
| 0001 0111 | 23 | 17 | ETB | ␗ | ^W | 区块传输结束 |
| 0001 1000 | 24 | 18 | CAN | ␘ | ^X | 取消 |
| 0001 1001 | 25 | 19 | EM | ␙ | ^Y | 连线介质中断 |
| 0001 1010 | 26 | 1A | SUB | ␚ | ^Z | 替换 |
| 0001 1011 | 27 | 1B | ESC | ␛ | ^[ | 退出键 |
| 0001 1100 | 28 | 1C | FS | ␜ | ^\ | 文件分割符 |
| 0001 1101 | 29 | 1D | GS | ␝ | ^] | 组群分隔符 |
| 0001 1110 | 30 | 1E | RS | ␞ | ^^ | 记录分隔符 |
| 0001 1111 | 31 | 1F | US | ␟ | ^_ | 单元分隔符 |
| 0111 1111 | 127 | 7F | DEL | ␡ | ^? | Delete字符 |
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用一至四个字节对Unicode字符集中的所有有效编码点进行编码,属于Unicode标准的一部分,最初由肯·汤普逊和罗布·派克提出。[2][3]由于较小值的编码点一般使用频率较高,直接使用Unicode编码效率低下,大量浪费内存空间。UTF-8就是为了解决向后兼容ASCII码而设计,Unicode中前128个字符,使用与ASCII码相同的二进制值的单个字节进行编码,而且字面与ASCII码的字面一一对应,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码方式。
自2009年以来,UTF-8一直是万维网的最主要的编码形式(对所有,而不仅是Unicode范围内的编码)(并由WHATWG宣布为强制性的“适用于所有事物(for all things)”,[4]截止到2019年11月, 在所有网页中,UTF-8编码应用率高达94.3%(其中一些仅是ASCII编码,因为它是UTF-8的子集),而在排名最高的1000个网页中占96%。[5] 其它的多字节编码方式如Shift JIS和GB 2312仅有0.3%和0.2%的占有率。[6][7][1]Internet邮件联盟(Internet Mail Consortium, IMC)建议所有电子邮件程序都能够使用UTF-8展示和创建邮件,[8] W3C建议UTF-8作为XML文件和HTML文件的默认编码方式。[9]互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码[10]。互联网邮件联盟(IMC)建议所有电子邮件软件都支持UTF-8编码。[11]
Unicode字符的比特被分割为数个部分,并分配到UTF-8的字节串中较低的比特的位置。在U+0080的以下字符都使用内含其字符的单字节编码。这些编码正好对应7比特的ASCII字符。在其他情况,有可能需要多达4个字符组来表示一个字符。这些多字节的最高有效比特会设置成1,以防止与7比特的ASCII字符混淆,并保持标准的字节主导字符串运作顺利。
UTF-8的编码方式
UTF-8是UNICODE的一种变长度的编码表达方式《一般UNICODE为双字节(指UCS2)》,它由肯·汤普逊(Ken Thompson)于1992年建立,现在已经标准化为RFC 3629。UTF-8就是以8位为单元对UCS进行编码,而UTF-8不使用大尾序和小尾序的形式,每个使用UTF-8存储的字符,除了第一个字节外,其余字节的头两个比特都是以”10”开始,使文字处理器能够较快地找出每个字符的开始位置。
但为了与以前的ASCII码兼容(ASCII为一个字节),因此UTF-8选择了使用可变长度字节来存储Unicode:
(注意:不论是Unicode (Table 3.7) [12],还是ISO 10646 (10.2 UTF-8) [13],目前都只规定了最高码位是0x10FFFF的字符的编码。下表中表示大于0x10FFFF的UTF-8编码是不符合标准的。)
| 码点的位数 | 码点起值 | 码点终值 | 字节序列 | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
|---|---|---|---|---|---|---|---|---|---|
| 7 | U+0000 | U+007F | 1 | 0xxxxxxx |
|||||
| 11 | U+0080 | U+07FF | 2 | 110xxxxx |
10xxxxxx |
||||
| 16 | U+0800 | U+FFFF | 3 | 1110xxxx |
10xxxxxx |
10xxxxxx |
|||
| 21 | U+10000 | U+1FFFFF | 4 | 11110xxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
||
| 26 | U+200000 | U+3FFFFFF | 5 | 111110xx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
|
| 31 | U+4000000 | U+7FFFFFFF | 6 | 1111110x |
10xxxxxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
Unicode编码和UTF-8以及ASCII等有何区别
1. Unicode:抽象字符集和标准
Unicode (统一码) 是一个国际标准,它回答了“哪个字符对应哪个数字”的问题。
- 定义: 它定义了一个庞大的字符集合,并为集合中的每个字符分配了一个唯一的、不可变的数字,称为**代码点 (Code Point)**,格式通常是
U+XXXX(十六进制)。- 例如:符号
π的Unicode代码点是U+03C0。
- 例如:符号
- 覆盖范围: 它旨在覆盖全球所有已知的书写系统、标点符号、技术符号和表情符号 Emoji。
- 与字节无关:
Unicode本身只是一个索引表。它不关心这些数字最终在计算机中占用多少字节,那是编码方式UTF-s的任务。
2. UTF-8:Unicode 的具体编码实现
UTF-8 Unicode Transformation Format - 8-bit) 是一种变长的编码方案,它回答了“如何将 Unicode 代码点存进计算机”的问题。
- 设计原则: 效率与兼容性。
- 它将
Unicode代码点转换为 1 到 4 个字节的序列。 - 兼容 ASCII: 它是
Unicode编码方式中最独特的一点。对于 ASCII 范围内的字符 (如英文字母),UTF-8编码后只占用 1 个字节,且与ASCII编码完全相同。 - 变长优势: 常用字符(英文)占用空间小,生僻字符占用空间大,实现了存储空间的最优化。
- 它将
- 关系: UTF-8 是实现 Unicode 标准的一种方式。 所有的 UTF 格式
UTF-8、UTF-16、UTF-32都是为了将Unicode字符集的内容以字节形式表现出来。
3. $\text{ASCII}$:历史悠久的字符集和编码
ASCII(American Standard Code for Information Interchange) 是计算机发展早期的标准,它既是字符集,也是一种固定长度的编码。
- 定义: 仅定义了 128 个 字符(使用 7 位二进制,即 1 字节中的低 7 位)。
- 包括大小写英文字母、数字 0-9、基本的标点符号和控制字符。
- 局限性: 无法表示任何其他语言的字符(如中文、希腊文、带重音的欧洲字母等)。这是导致后来出现
Unicode的主要原因。 - 关系:
- ASCII 是 Unicode 的子集。
ASCII的 128 个字符在Unicode中有完全相同的代码点 (U+0000到U+007F)。 - ASCII 字符在 UTF}-8 编码下与原 ASCII 编码完全相同(都是 1 字节)。这保证了
UTF-8能够向后兼容旧的英文文本文件。
- ASCII 是 Unicode 的子集。
总结图示
您可以将它们的关系理解为:
ASCII ∈ Unicode
Unicode 是一个包含所有字符的超大宇宙。
UTF-8 是一种将这个宇宙中的所有星球(字符)打包运输(编码)的规则。
ASCII 只是这个宇宙中最早、最小的一个角落(基础英文和符号),但它的规则被 Unicode 和 UTF-8完整继承了下来。
| 名称 | 类型 | 核心作用 | 编码大小 | 关系总结 |
|---|---|---|---|---|
| Unicode | 抽象字符集 / 标准 | 为世界上每个字符分配一个唯一的数字身份(代码点 Code Point)。 | 无关(它只定义身份)。 | 目标和蓝图。 |
| UTF-8 | 具体编码方式 | 定义如何将 Unicode 代码点转换成实际的字节序列存储或传输。 | 1 到 4 个字节(可变长)。 | 实现 Unicode 的最流行方式。 |
| ASCII | 过时字符集 / 编码 | 为 128 个 基本英文字符和控制符分配代码。 | 固定 1 个字节(7 位)。 | Unicode 和 UTF-8 的子集和基础。 |
我们可以这么理解计算机是如何呈现字符与表情的: 用户通过输入法输入一个字符或者表情(输入法也有自己的编码规范)你的系统会根据目前的编码规范去查询Unicode码表,找到对应编码后通过自己的UTF-8或其它规范将其转换为操作系统可以理解的字节序列。
- 用户输入/程序使用字符 → 比如输入“😊”
- 系统查 Unicode 表 → 找到它的码点:U+1F60A
- 用 UTF-8 编码 → 转成字节序列:
F0 9F 98 8A,存入文件或发送到网络- 另一台设备收到字节 → 用 UTF-8 解码,还原出 U+1F60A
- 操作系统/浏览器查字体 → 找到“U+1F60A 对应的字形”,渲染出 😊