在之前的一篇文章我们有提到Ai模型的选择,本章我们将就GPT-5以及Grok-4的推出做一篇新的推荐,同时本次我们还将重点推荐我已经使用很久的国产模型Qwen-3.
在对大模型语言模型进行能力评测时需要对多我i都来进行评测以确保其合理性与可信度。评测中需要测试模型的基础能力(譬如数学能力、代码编写能力、指令遵守能力、多轮对话能力、文字写作能力、复杂问题解答能力、复杂问题解答能力(英文语境)、外语能力),这些测试项几乎包含了日常使用的所有场景,足以聚焦实际并给出可参考数据。
该文章将会你们提供来自于LMArena对各家新模型进行的多项功能测试排名(数据来源于Hugging face社区、Discord社区以及官方和第三方评测 ),在此排名中我会截取前几名的数据,完整的数据请移步至LMArena自行观阅。
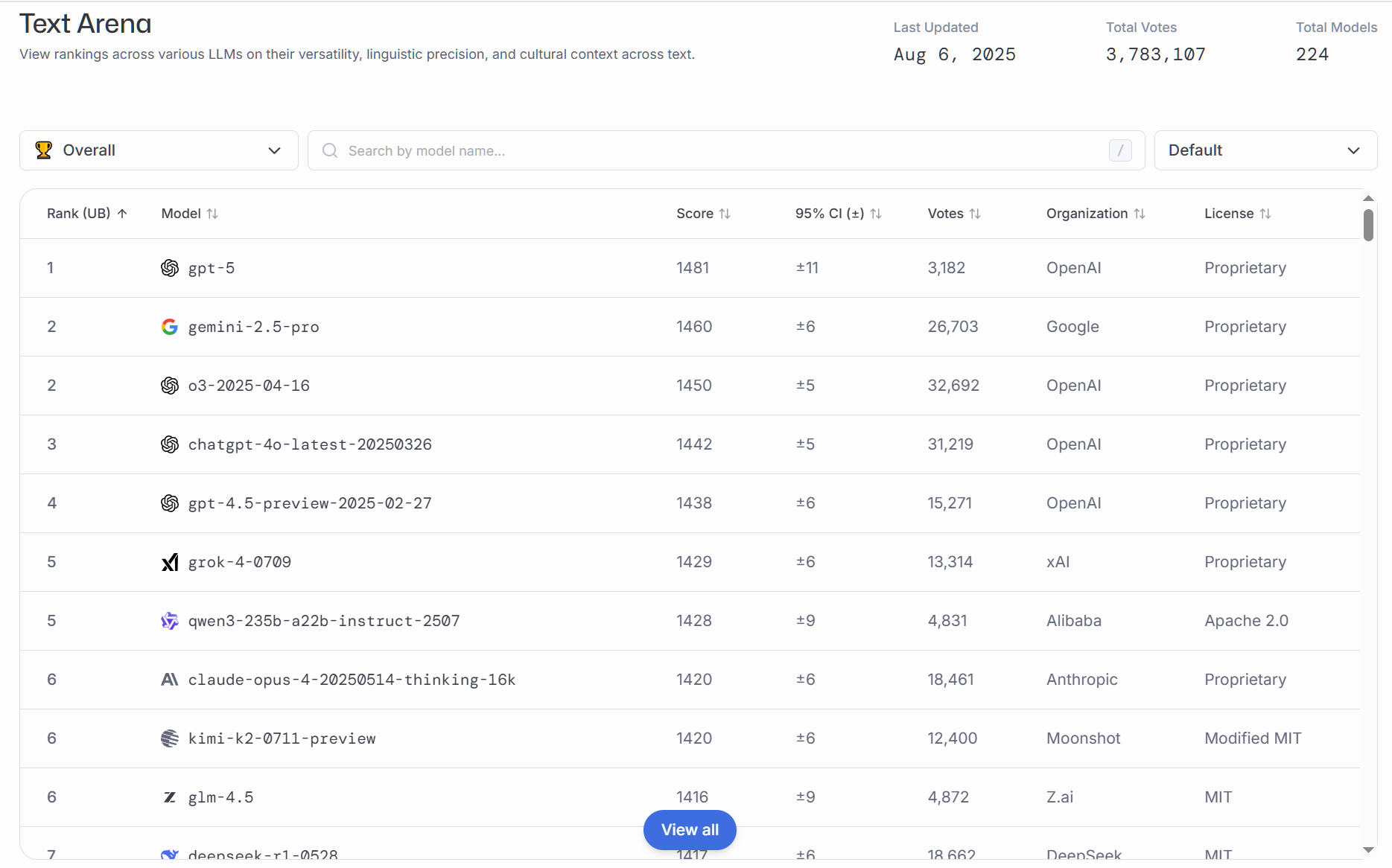
### 综合排名
综合能力通常使用跨学科、跨任务的数据集进行评测,目的是:
评估模型的通用性:检验模型能否在不同领域(如常识问答、推理判断、阅读理解等)都表现稳定。
揭示能力瓶颈:通过汇总各子任务得分,发现模型在概念理解、逻辑推理、语义匹配等方面的薄弱环节。
指导迁移学习与迭代优化:综合分数能帮助研发团队判断下一步是加强预训练规模,还是优化微调策略。
单项排名
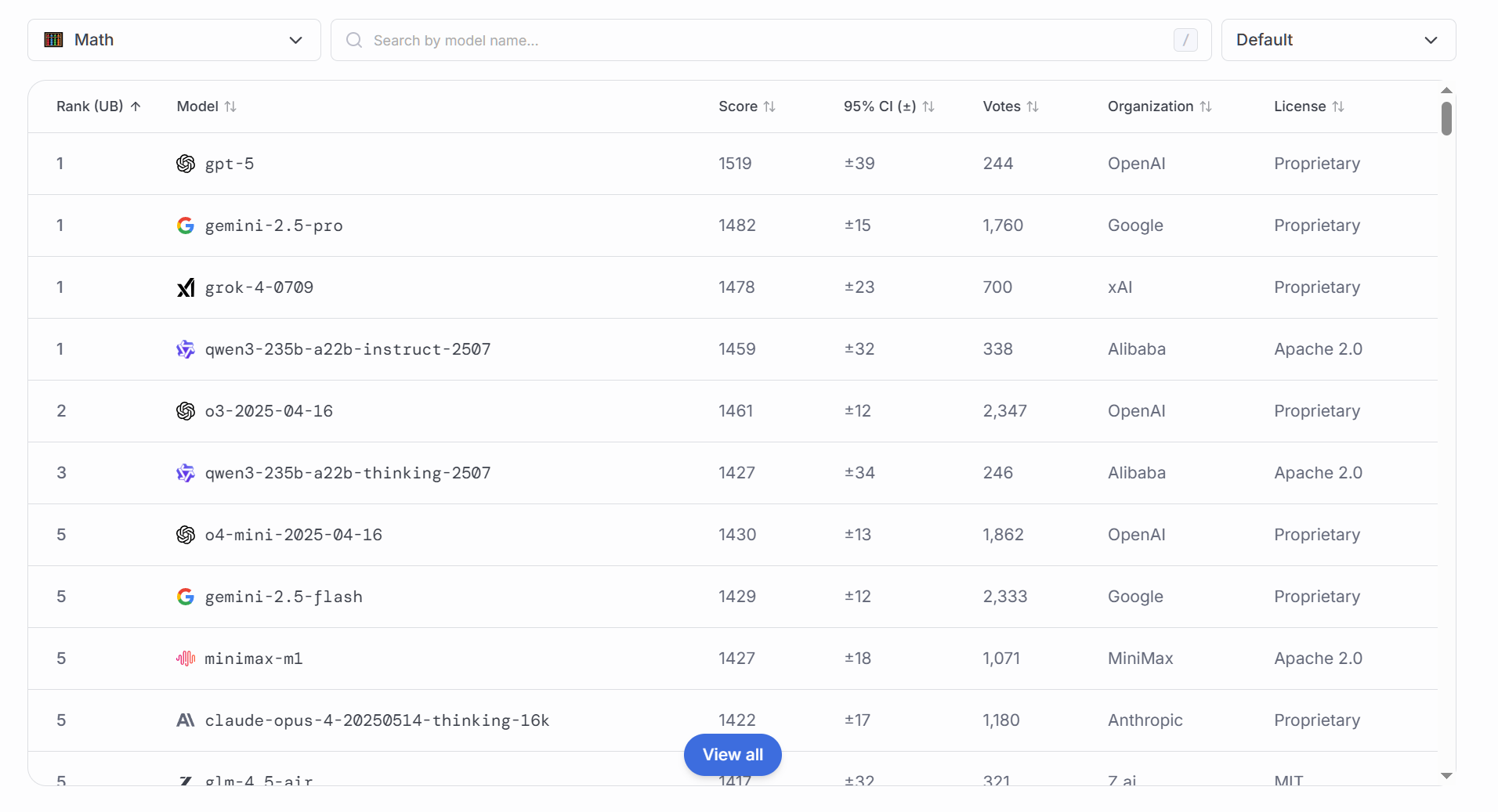
### 数学
测评内容通常包括算术运算、代数推导、几何判断和概率统计题目,原因在于:
验证模型的逻辑推理与符号化处理:数学问题要求精确计算和严密推导,能体现模型的“符号运算”能力。
保障应用安全性:在财务分析、科学研究等场景中,错误的数学计算会带来严重后果,必须确保模型结果准确。
推动“算术思维”研究:通过分析错误类型(如漏项、进位错误、概念混淆),促进更高效的算法设计。
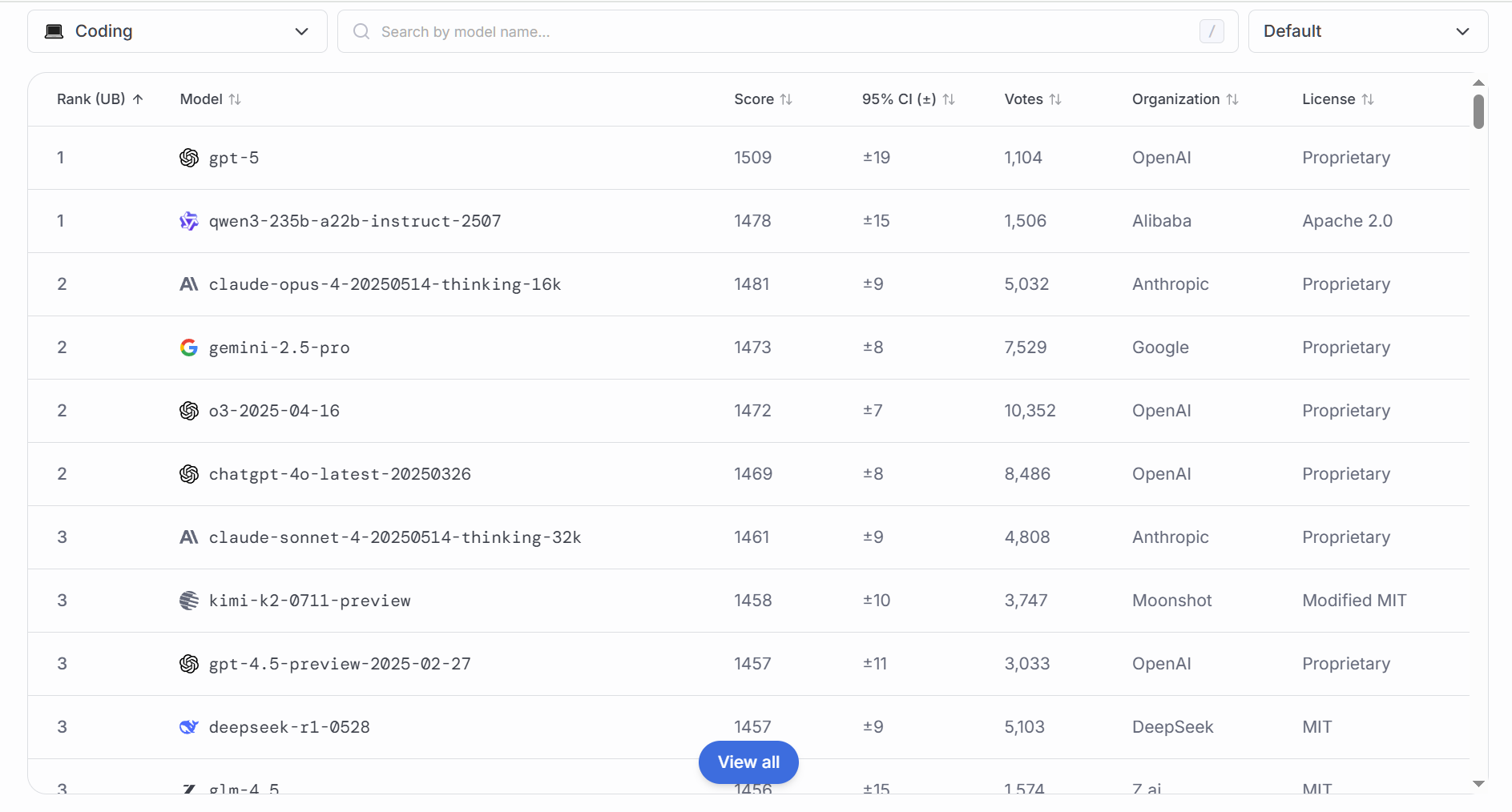
### 代码
通常评测从多种编程语言(Python、JavaScript、C++等)和不同难度级别的编程题目入手,理由包括:
衡量模型执行具体任务的实用性:代码生成能力是AI在软件开发、数据处理、自动化运维等场景中的核心指标。
评估语法理解与逻辑构造:编程题要求模型不仅要理解语言语法,还要嵌套控制流、调用库函数,以及处理异常。
促进人机协作:高水平的代码建议可以帮助开发者提升开发效率,降低出错率。
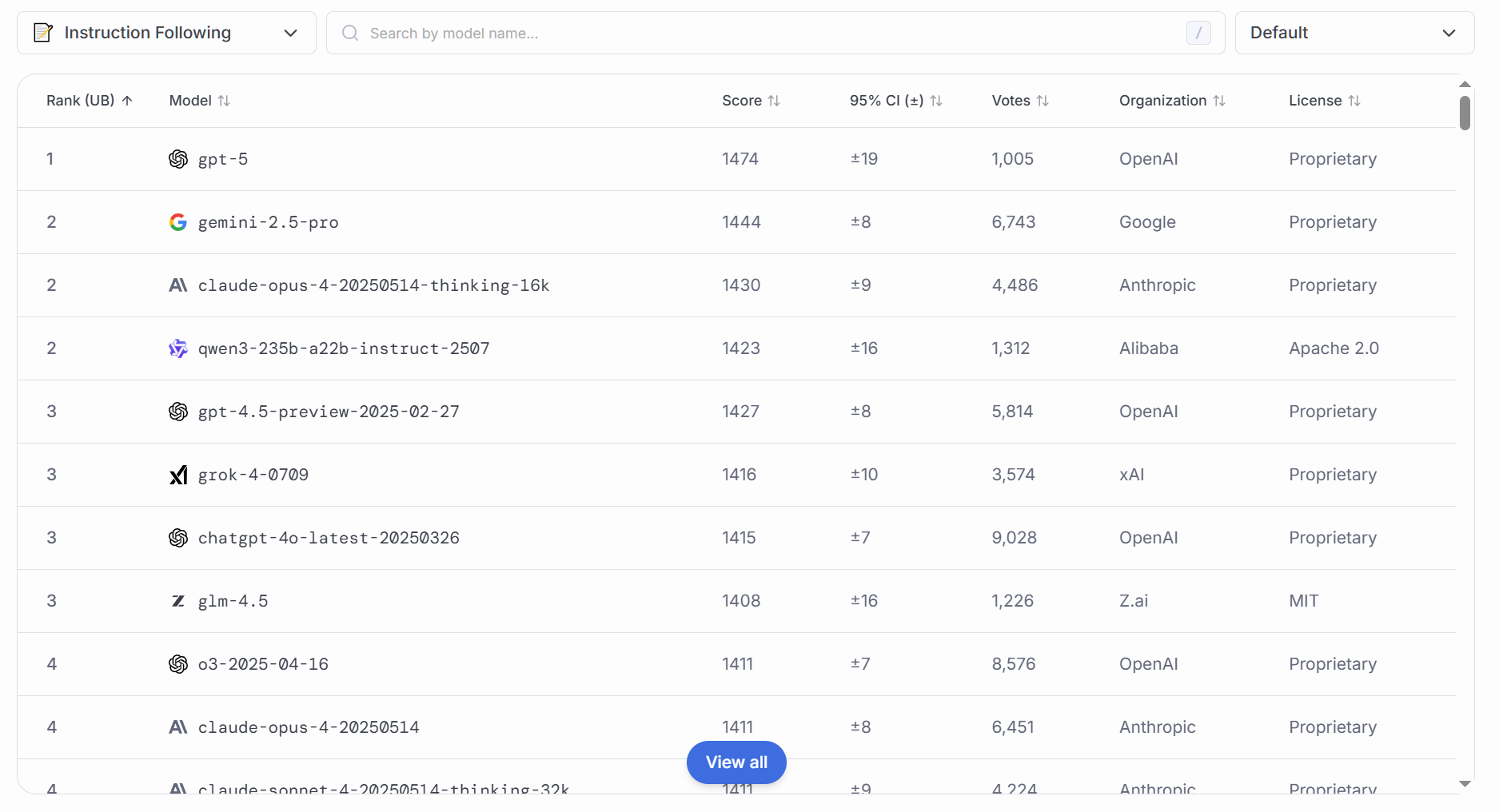
### 指令遵守
此维度测试模型对用户指令的准确响应性,包括“格式要求”、“风格约束”、“禁止某些话题”等,测评意义在于:
保障输出安全与合规:在敏感性话题、商业机密、隐私信息等场景,模型必须严格遵守约束。
提升用户体验:良好的指令执行力让模型行为可预测、稳定,满足用户个性化需求。
支持可控生成研究:通过测评进一步优化Prompt设计和强化学习调优(RLHF)策略,从而增强模型可控性。
### 多轮对话
侧重模型在上下文连贯、话题跟踪、参考先前信息等方面的表现,其重要性体现在:
模拟真实人机交互场景:客服、咨询、陪聊等应用要求模型在多轮对话中保持一致性与连贯性。
检测记忆与上下文利用:评估模型能否“记住”前文要点,并在后续响应中引用、校正或扩展。
防止“上下文丢失”:在长对话或复杂任务中,若模型频繁丢失信息,会导致用户体验下降或任务失败。
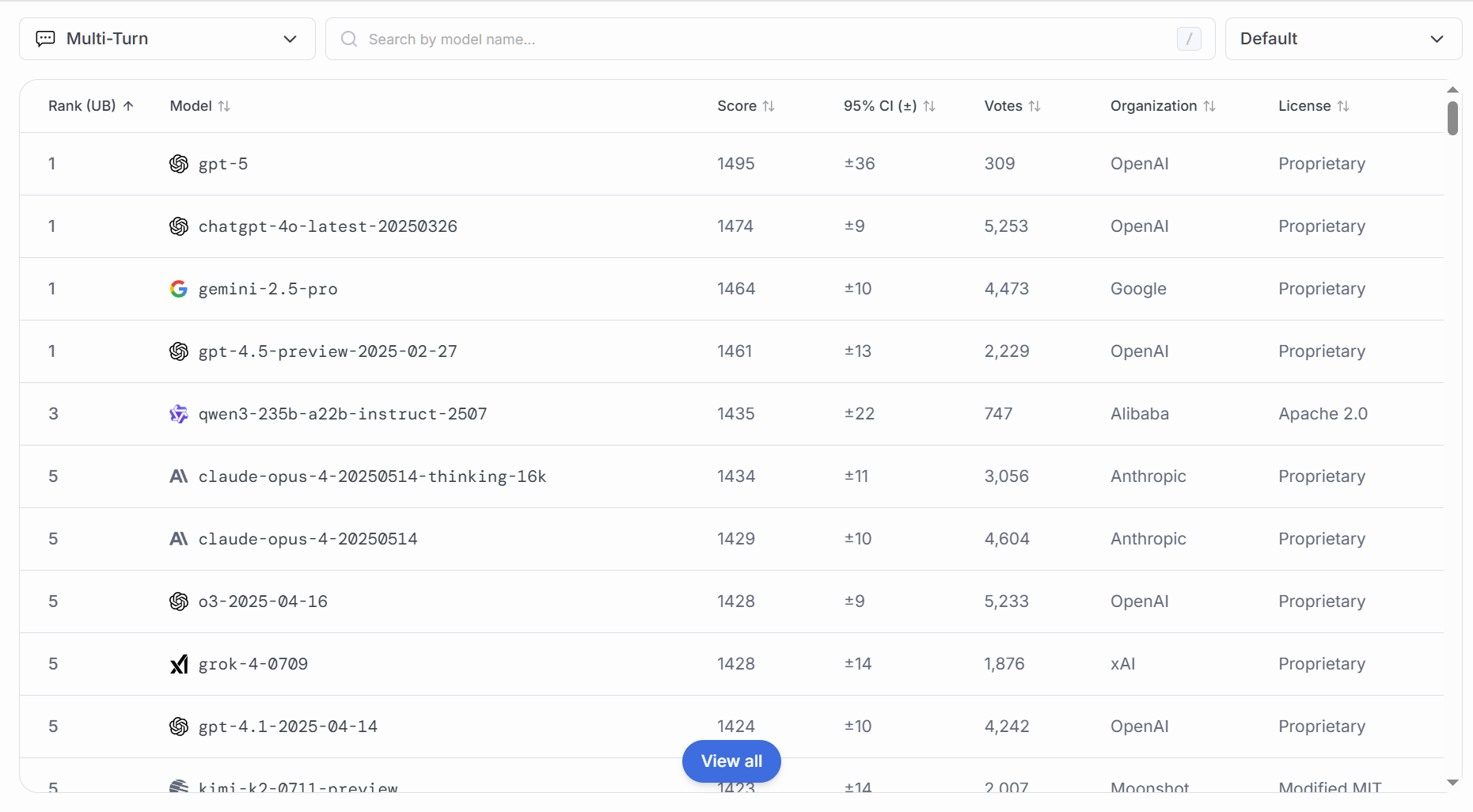
### 文字书写
包括议论文、说明文、创意写作等多种文体,测评原因如下:
衡量模型的语言组织与风格掌控:写作能力体现了模型对篇章结构、逻辑衔接、修辞手法的综合运用水平。
评估可读性与吸引力:高质量文本不仅要内容正确,还要易读、有说服力,符合目标读者的审美与需求。
应用于内容创作场景:新闻撰写、营销文案、学术论文初稿等领域,对写作质量要求极高。
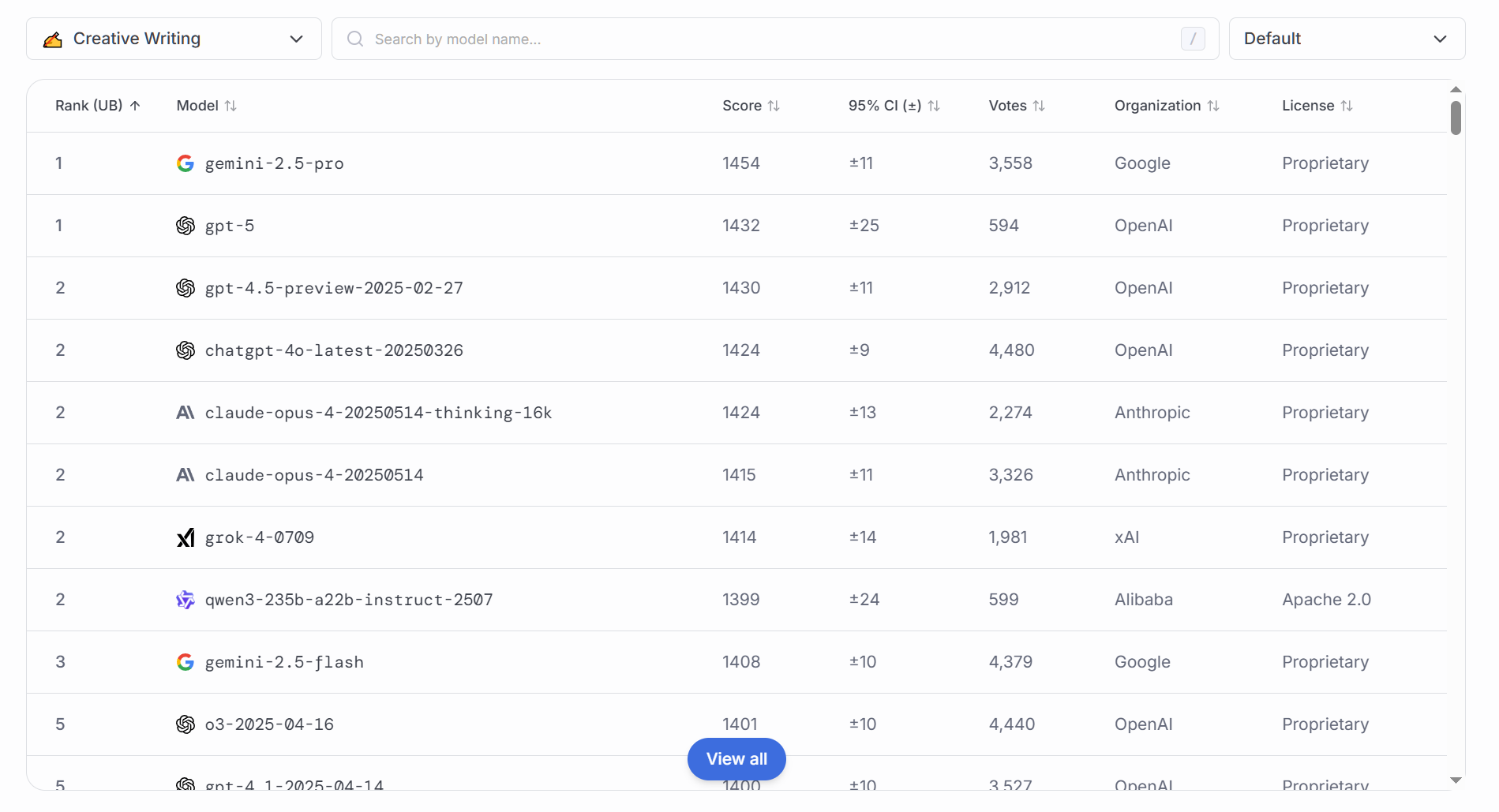
### 复杂问题解答
重点在于多步骤推理、跨领域知识融合以及解决开放性问题,测评意义包括:
验证模型的综合推理与决策能力:面对非结构化问题,需要模型检索、筛选并组合多种知识。
揭示弱项与知识空洞:通过开放问题反馈,研发者能够识别并补齐知识盲区。
支持高级应用场景:法律咨询、战略规划、科研假设验证等场景都依赖于模型的复杂问题解答能力。
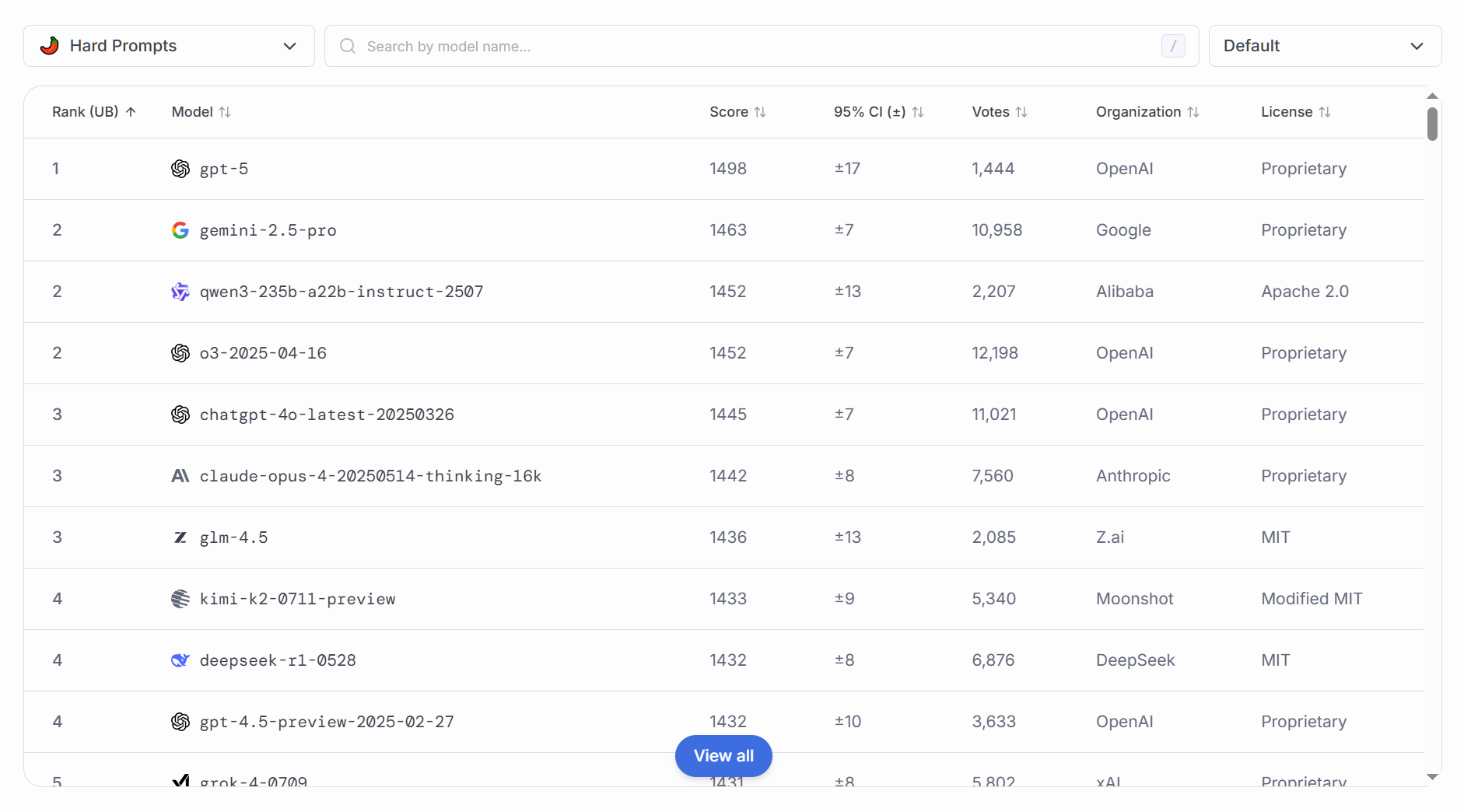
### 复杂问题解答(英文语境)
尽管与前一项类似,但在英语语境下测试,目的是:
消除语言迁移偏差:模型在多语言训练后,往往在非母语环境下表现略逊,需专门测评。
确保跨语言一致性:在国际化部署时,模型应在英文环境下提供与母语相当的推理深度与表达准确性。
检测文化与语境理解:很多开放性问题涉及西方文化、法律体系、习俗背景,仅在中文环境中难以发现偏差。
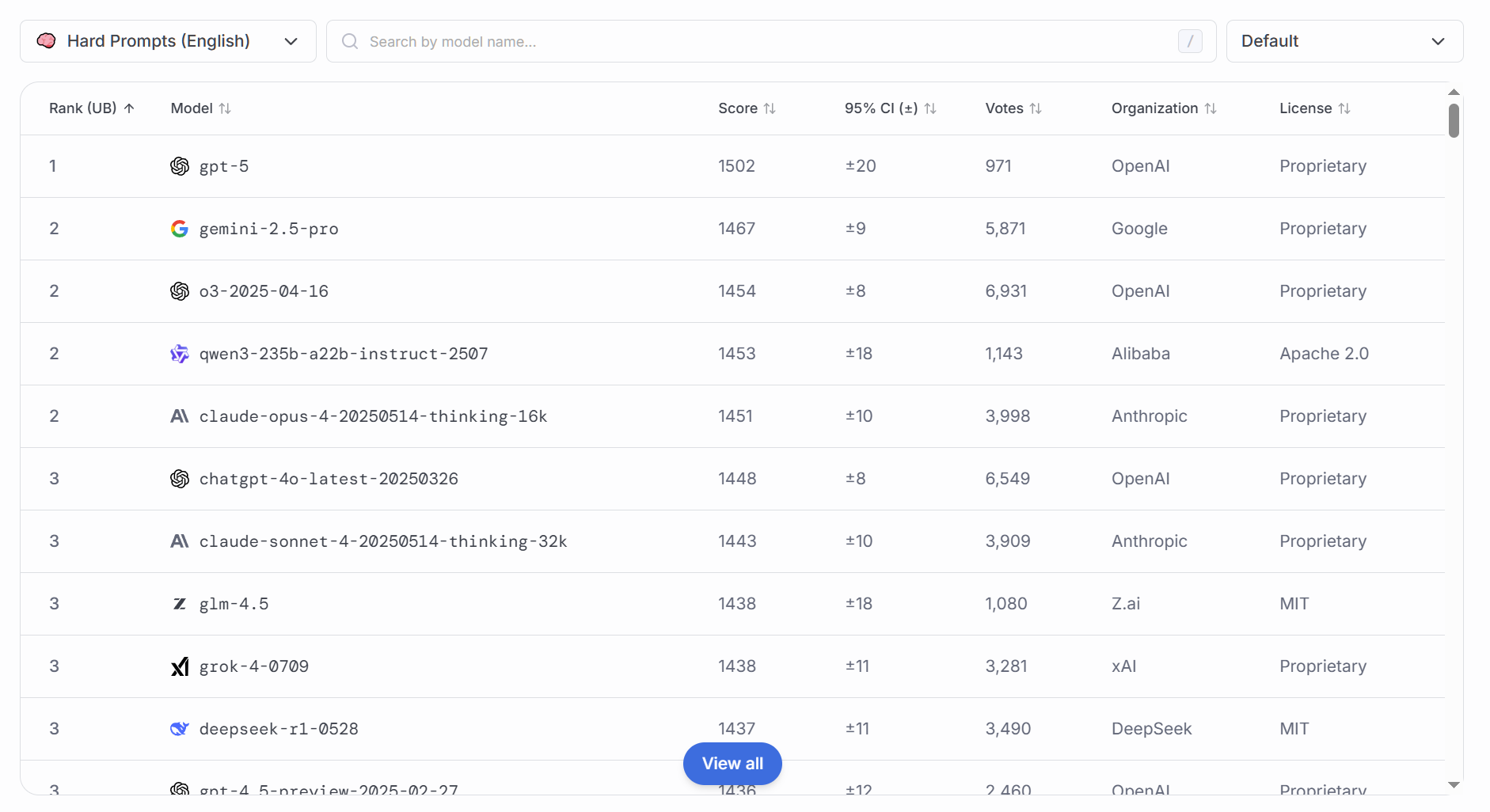
### 中文能力(本土化)
包括词汇量、语法理解、成语典故、文言文等评测,原因在于:
满足中文母语用户需求:中文表达习惯、文化底蕴与英文有本质差异,需专门测试。
避免翻译腔与语义误解:直接生成中文文本比翻译更自然流畅,降低歧义。
支持本土化应用:在中国市场的智能客服、教育辅导、内容创作等场景,中文能力是核心竞争力。
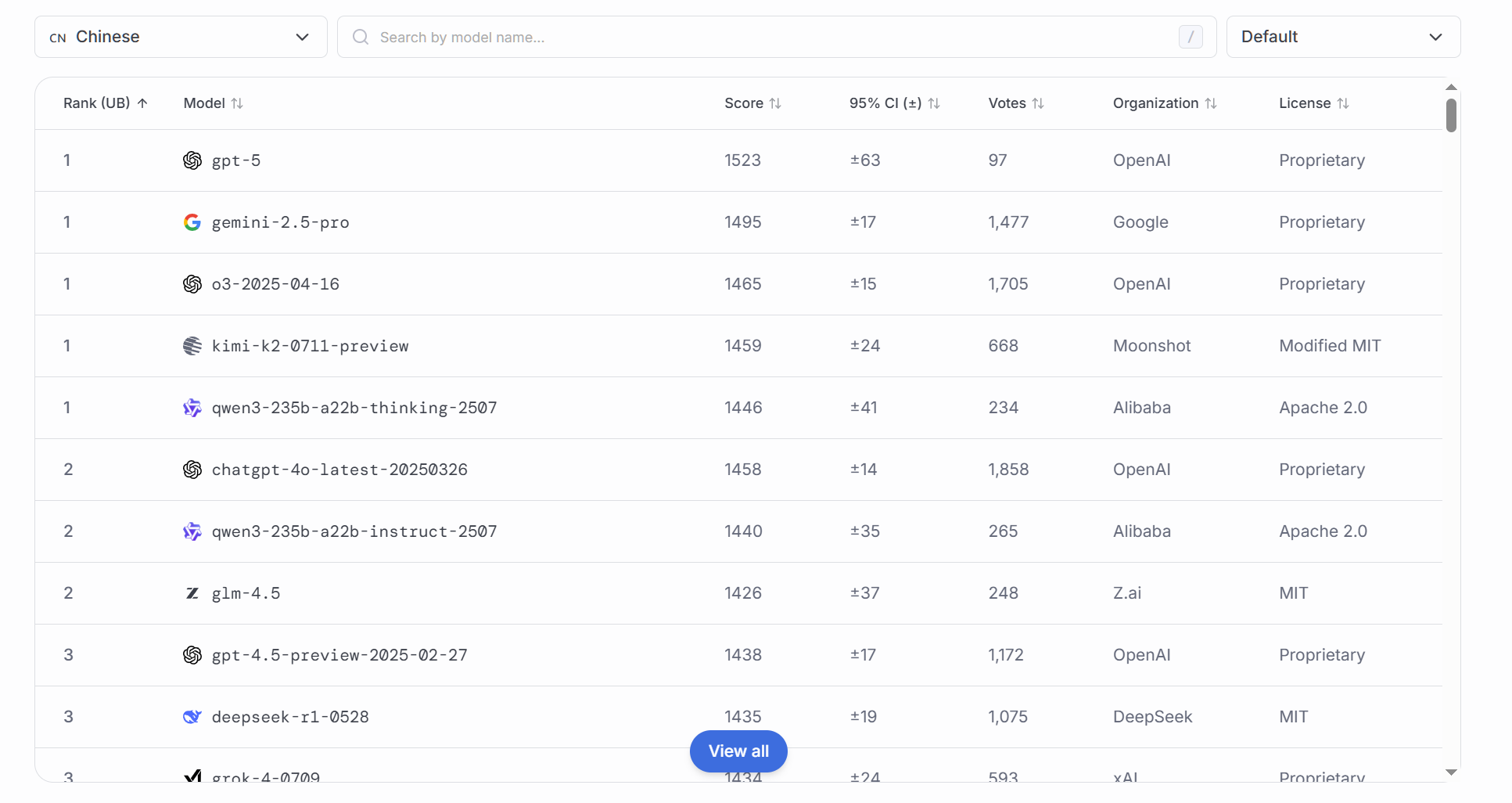
选型推荐
对Ai了解不多且无任何了解欲望:
国产:
Qwen3, Qwen3(非通义千问)国外:
ChatGPT
有能力使用海外服务但需求不明确且没了解欲望:
ChatGPTGeminiQwen
可以自由使用海外服务且需求复杂:
- 文字撰写:**
ChatGPT>Grok>Gemini** - 代码编写:
Claude>ChatGPT>Gemini - 数学及推理:
Gemini>Qwen3 - 中文可选:
ChatGTP>Qwen3>Grok - 实时网络信息获取:
Grok>Gemini
在此我们将要特殊说明Perplexity的不同,Perplexity是一个集成多模型性的服务,完全可以根据需求实时选择既有模型及服务:
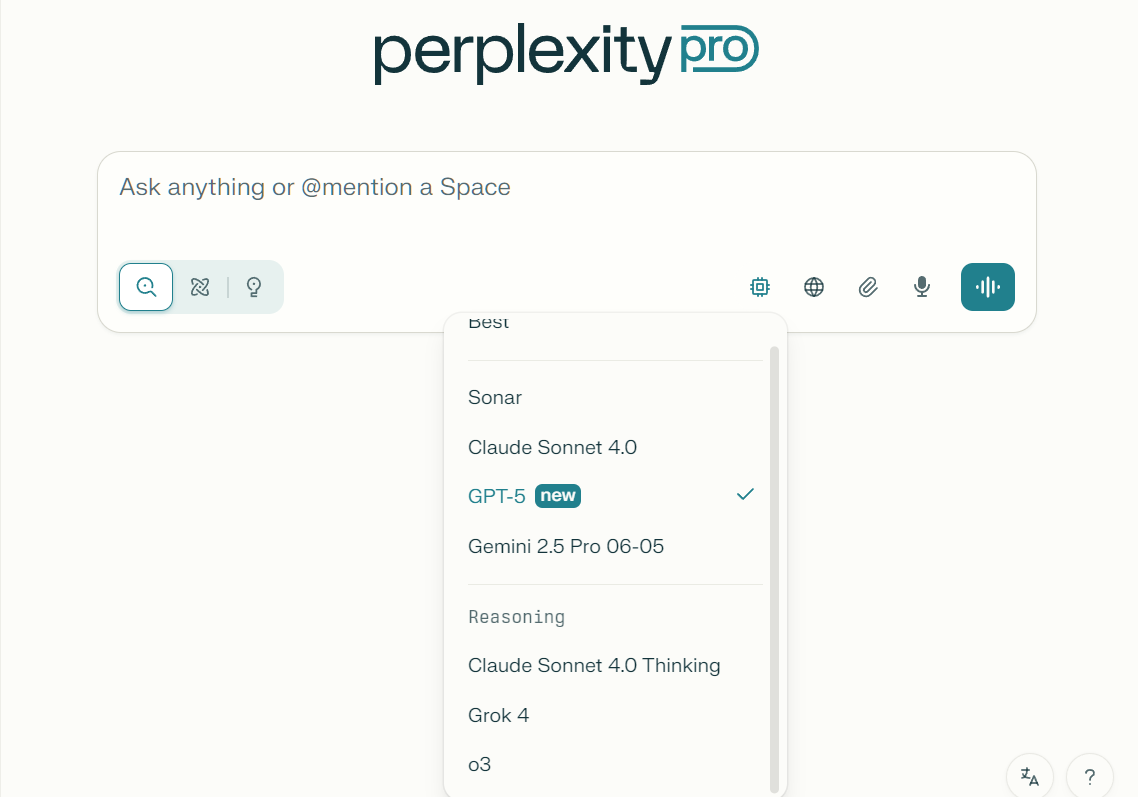
Perplexity为集成服务,各位用户在使用时可参考上面的推荐选择合适的模型,或者是选择默认的模型,Perplexity将会根据你的问题难度自动选择合适的Ai模型。需要进行深度思考时你可以在提示词中提出,直接告知本轮对话需要进行深度思考,随后便会自动调用思考模型。
各家模型可能存在的问题:
ChatGPT在多轮对话后有降智的表现,有时候会难以联系上下文。Perplexity也会出现与GPT类似的问题,可能与调用的模型有关,适时观察并切换。Gemini的线性代数和高等数学的数学公式会有渲染问题(仅仅是Flash模型,Pro模型不会有这种问题)。Qwen3有较多的关键词检测,好的提示词可以一定程度上绕过检测,但依旧有风险系数较高的提示词(比如政治人物的名字和历史事件),此外Qwen3的OCR识图能力稍弱,发送图片时尽量保证图片清晰没有变形。Claude只建议用于代码编写以及深入研究某课题时使用,其基础能力较差,但是写作能力也是可以的
每个人的做事和问答习惯均不同,具体的使用效果请参考实际,本文仅提供个人见解,不对任何使用问题负责人。请各位读者能在选择中融入自己的见解。